
EPrints Technical Mailing List Archive
See the EPrints wiki for instructions on how to join this mailing list and related information.
Message: #09948
< Previous (by date) | Next (by date) > | < Previous (in thread) | Next (in thread) > | Messages - Most Recent First | Threads - Most Recent First
Re: [EP-tech] Still about PDF that always get downloaded, the source code is different
- To: David R Newman <drn@ecs.soton.ac.uk>
- Subject: Re: [EP-tech] Still about PDF that always get downloaded, the source code is different
- From: "Agung Prasetyo W." <prazetyo@gmail.com>
- Date: Sat, 25 Jan 2025 22:42:24 +0700
CAUTION: This e-mail originated outside the University of Southampton.
Hi David,
I have tried the command:
<EPRINTS_PATH>/bin/epadmin redo_mime_type <ARCHIVE_ID> eprint <EPRINT_ID>
I have tried the command:
<EPRINTS_PATH>/bin/epadmin redo_mime_type <ARCHIVE_ID> eprint <EPRINT_ID>
as you gave, and it works.
To see the changes from the command above, I have to open it using incognito mode, because if from the same browser, then sometimes there are still files that must be downloaded.
Thanks a lot David
Thanks a lot David
Thank you.
Regards,
Agung PW
On Sat, 25 Jan 2025 at 17:13, David R Newman <drn@ecs.soton.ac.uk> wrote:
Hi Agung,
The missing mime type is likely to be the issue with yours downloading and other being viewed in browser. The mime type is used to serve the file when requested. With an unknown mime type your browser will not know that it can be viewed in browser, so will take the only other option, which is to download it.
Fortunately, EPrints has a way of analysing pre-uploaded files and determining their mime types and updating the database. This in turn allows EPrints to serve the files with the right mime type and should allow PDFs to be viewed in browser. Ultimately you probably want to run this across all eprints, as you probably don't know which are affected. However, it is probably best to first to do it on the single missing mime type example you gave in your screenshot:
<EPRINTS_PATH>/bin/epadmin redo_mime_type <ARCHIVE_ID> eprint <EPRINT_ID>
If this fixes the issue, then you can just remove the <EPRINT_ID> part and this will regenerate the mime types for all eprint records. If it does not work (and maybe why it did not work in the past) is probably because of a dependency needed for analysing files to determine their mime type is missing or the configuration in EPrints for performing this task has changed. The main dependency is the Unix file command. Maybe test a PDF with this from the command line:
file my_document.pdf
The output should be something like:
my_document.pdf: PDF document, version 1.5
If it says the file command cannot be found then you need to install the package called "file" on your Linux operating system. If the epadmin redo_mime_type command above still does not work, then I would advise testing the file command directly against the file under your documents directory, as there may be something odd about this file that means its mime type cannot be determined (or at least not as a PDF). If that is the case then try some other PDFs under you documents directory that have the same issue with viewing vs. downloading.
If the file command does identify your PDF files as PDFs then the only remaining problem is likely to be that the configuration for determining this has been changed. This configuration is under EPRINTS_PATH/lib/cfg.d/media_info.pl. Check this has not been modified compared to the version of EPrints you installed and that there is no other cfg.d/media_info.pl file. If there is then either revert changes or move the other version(s) of cfg.d/media_info.pl out of the way and try running the redo_mime_type command on the single eprint you showed in your screenshot.
Hopefully, you will find the the epadmin redo_mime_type command works immediately and you do not have to bother with installing packages or reverting / removing EPrints configuration. However, if you still have to do this and it is not working, I am not sure what further to advise.
Regards
David Newman
On 24/01/2025 11:33 pm, Agung Prasetyo W. wrote:
CAUTION: This e-mail originated outside the University of Southampton.Hi David,
After I look at file history, in the item that file pdf must download, there is no mime_type.
[REDACTED SCREENSHOT]
Does it affect the file?
Thank you.
Regards,Agung PW
On Sat, 25 Jan 2025 at 05:54, Agung Prasetyo W. <prazetyo@gmail.com> wrote:
Hi David,
I don't know why, after I tried to upload a pdf file that was in one of the items, it turned out that the PDF could be displayed directly on the browser without having to download it first.
link that I just edited - OK : [REDACTED URL]
link that must be download - Not OK : [REDACTED URL]
Is it possible that users when uploading documents do not do it by clicking the Uploads menu or other actions that cause the pdf file document not to be uploaded properly? Then almost all thumbnails of the pdf document also do not appear. Whereas if I try to upload via Uploads, the thumbnail appears perfectly
[REDACTED SCREENSHOT]
[REDACTED SCREENSHOT]
Thank you.
Regards,Agung PW
On Sat, 25 Jan 2025 at 05:00, Agung Prasetyo W. <prazetyo@gmail.com> wrote:
HI David,
Our repo url is http://uat-repository.uph.edu/Sorry for the URL I sent privately because it is currently under repair.
Thank you.
Regards,Agung PW
On Sat, 25 Jan 2025 at 01:14, David R Newman <drn@ecs.soton.ac.uk> wrote:
Hi Agung,
It would be useful if you could share a URL for a page where when you click on a link for a PDF on this page it downloads rather than loads in browser. Then we can test if we get the same behaviour in our web browsers. If so, then I suspect I can probably analyse the HTTP requests and responses related to these and see how they differ from other repositories where the PDFs load in browser.
Regards
David Newman
On 24/01/2025 18:08, Agung Prasetyo W. wrote:
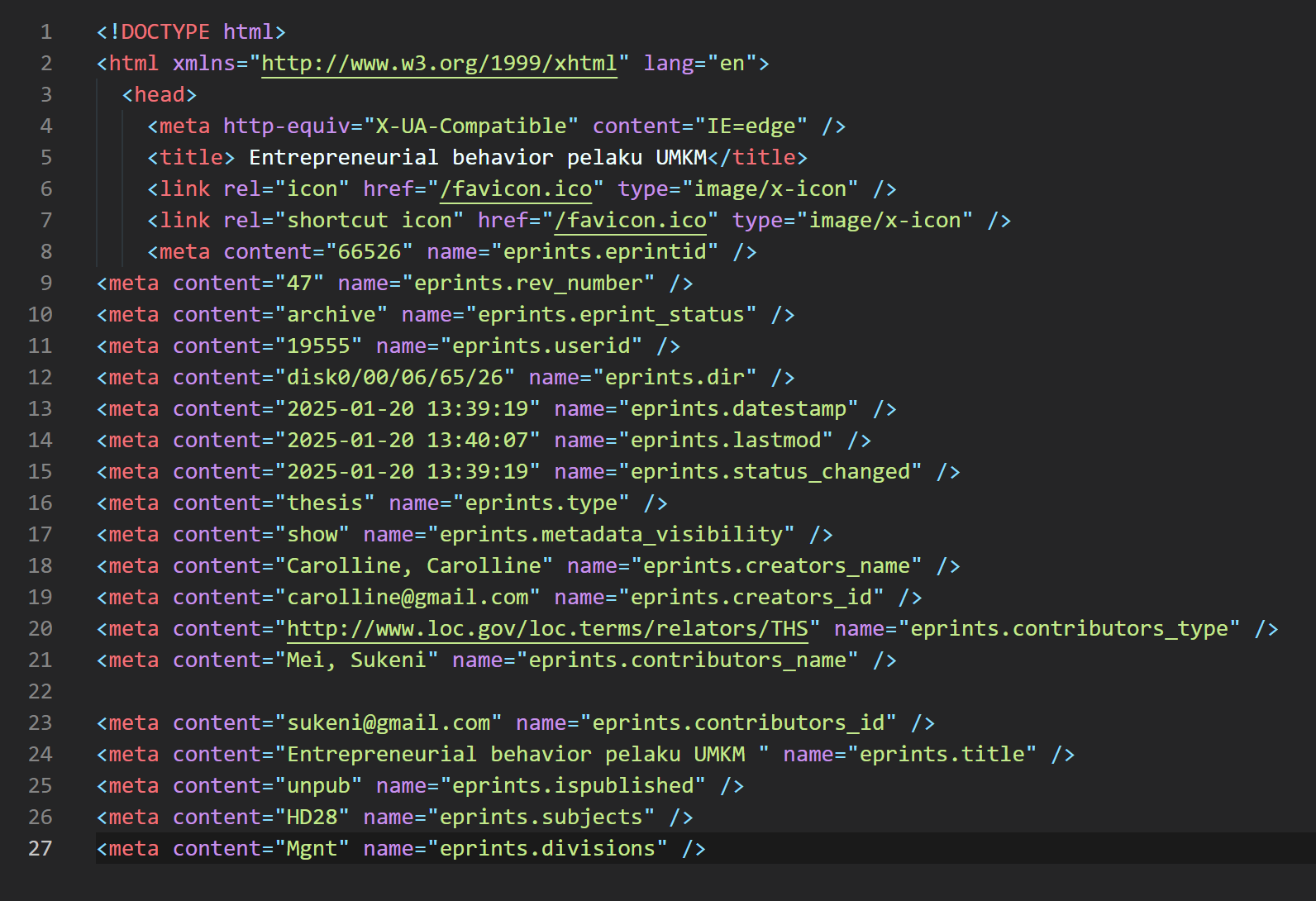
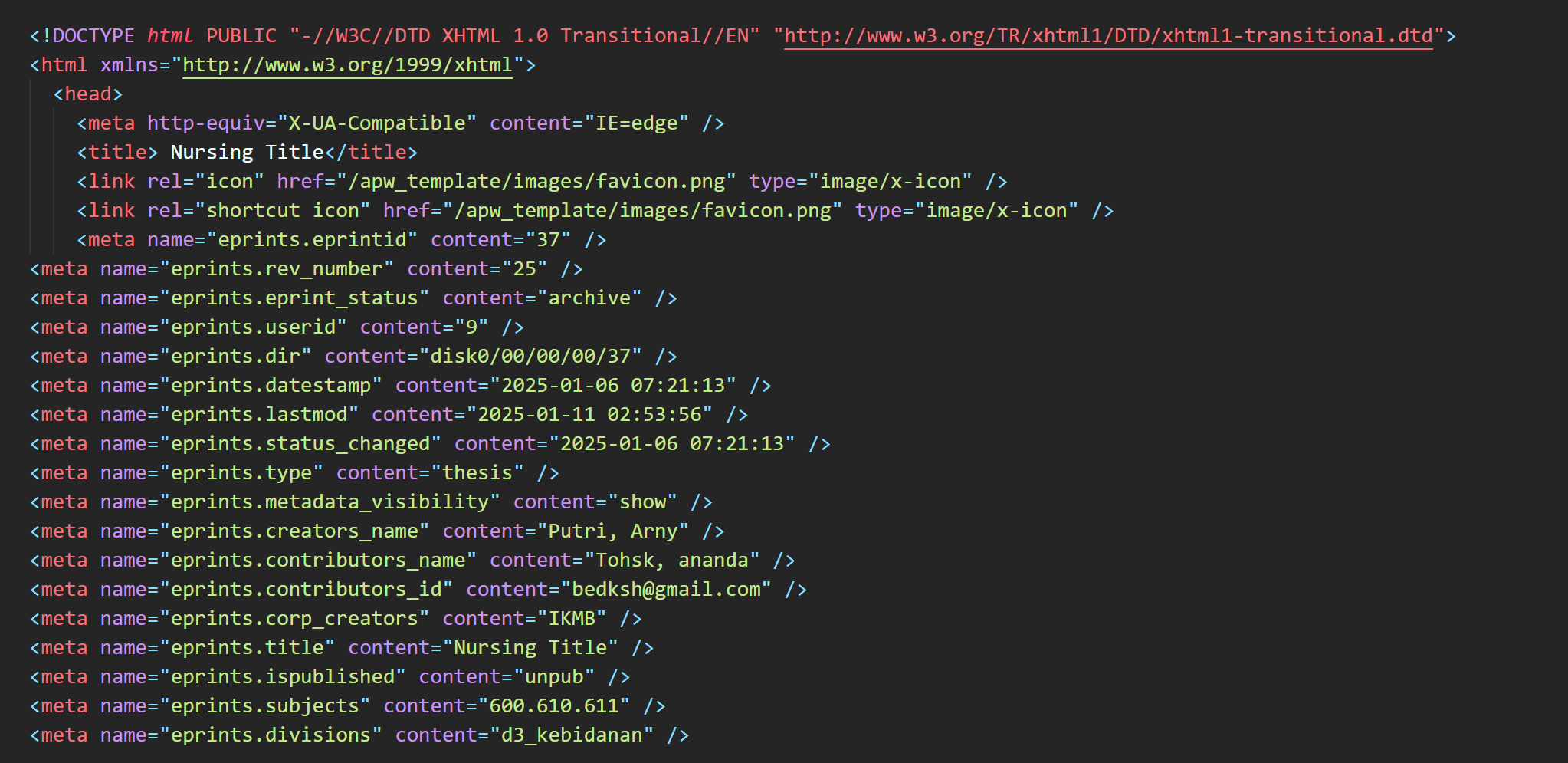
CAUTION: This e-mail originated outside the University of Southampton.CAUTION: This e-mail originated outside the University of Southampton.Continuing my previous question, when I display the source code from the summary, I see the html format is different.
For example, in my repo:
While the repo in general is like this:
Is this difference in the html rendering results that can cause the pdf to not open directly in the browser and have to be downloaded?
In what file if I want the html source code results to be the same as other eprints?
Thank you.
Regards,Agung PW
*** Options: https://wiki.eprints.org/w/Eprints-tech_Mailing_List *** Archive: https://www.eprints.org/tech.php/ *** EPrints community wiki: https://wiki.eprints.org/
- References:
- [EP-tech] Still about PDF that always get downloaded, the source code is different
- From: "Agung Prasetyo W." <prazetyo@gmail.com>
- Re: [EP-tech] Still about PDF that always get downloaded, the source code is different
- From: David R Newman <drn@ecs.soton.ac.uk>
- Re: [EP-tech] Still about PDF that always get downloaded, the source code is different
- From: David R Newman <drn@ecs.soton.ac.uk>
- [EP-tech] Still about PDF that always get downloaded, the source code is different
- Prev by Date: Re: [EP-tech] Still about PDF that always get downloaded, the source code is different
- Next by Date: [EP-tech] Request for Assistance: Slow Turnaround Time for EPrints Repository
- Previous by thread: Re: [EP-tech] Still about PDF that always get downloaded, the source code is different
- Next by thread: [EP-tech] Request for Assistance: Slow Turnaround Time for EPrints Repository
- Index(es):